
Matt Bidewell
An Intro to Distributed Systems - Part 1
2023-08-26
In today's interconnected and data-driven world, the concept of distributed systems has emerged as a fundamental pillar of modern computing. From cloud-based applications to online social networks, distributed systems play a pivotal role in enabling seamless communication, resource sharing, and fault tolerance across a network of interconnected devices. In this introductory exploration, we will delve into the essence of distributed systems, providing a high-level overview of their significance, functionalities, and the intricate problems they are designed to solve.
Understanding Distributed Systems
"A distributed system is a computing environment in which various components are spread across multiple computers (or other computing devices) on a network." - Splunk
In a general sense, a distributed system is a collection of autonomous computing devices that communicate with each other over a network. These devices, also known as nodes, are connected by a communication network and work together to achieve a common goal. Distributed systems are designed to enable the sharing of resources and information across a network of nodes, allowing for efficient data processing and fault tolerance.
Or - "A distributed system is one in which the failure of a computer you didn't even know existed can render your own computer unusable." as Leslie Lamport puts it.
Key Challenges in Distributed Systems
Distributed systems bring a host of unique challenges that differ from those encountered in traditional single-node systems. This post will be a high-level overview of the concepts and challenges of distributed systems.
Failure Detection
In a distributed system, several things can and will go wrong. For example, a connection is severed, a node crashes or a data centre floods. In a distributed system, it is important to be able to detect these failures and react to them (automatically). This is called failure detection.
Let's say we have two nodes communicating over HTTP. How will the node sending the message know if the receiver is still alive and can respond? The best it can do is make an educated guess based on the time it takes to respond. If the response takes too long, the node can assume the other node is dead and take action. This is called a timeout. The tricky part is deciding how long to wait before assuming the other node is dead. If you wait too long, you will have a slow system. If you wait too little, you will have a system that is too sensitive to network latency. In summary - failure detection is hard.
A distributed system might use ping to check if a node is alive. If the node does not respond to the ping, it is assumed to be dead. This is a simple example of failure detection. A heartbeat is another example of failure detection. A node sends a message to another node at regular intervals. If the node does not respond, it is assumed to be dead. The difference is the heartbeat tells listeners the client origin of the message is alive, while the ping tells listeners the server origin of the message is alive.
Replication
Data replication is a fundamental block of distributed systems. Replication is the process of storing the same data on multiple nodes. This is done to increase availability and fault tolerance. If one node goes down, the data is still available on other nodes. Replication is also used to increase performance. If a node is far away from the client, the data can be replicated on a node closer to the client. This is called data locality.
Implementing replication is challenging because it requires keeping replicas consistent with one another even in the face of failures. Let's take a look at the Chain replication, which provides a strong consistency guarantee, which to clients, looks like the data is on a single node.
In Chain Replication, processes are arranged in a chain, with a head and tail node. Clients will write to the head whilst reads are performed on the tail. The head node will then replicate the data to the next node in the chain. The next node will then replicate the data to the next node in the chain and so on. This ensures that all nodes in the chain have the same data. Once the tail node has applied the write command, it will reply up the chain with acknowledgement which can then reply to the sender that the write succeeded. If a node fails, the node before it in the chain will take over. If the head node fails, the tail node will take over. This ensures that the data is always available.
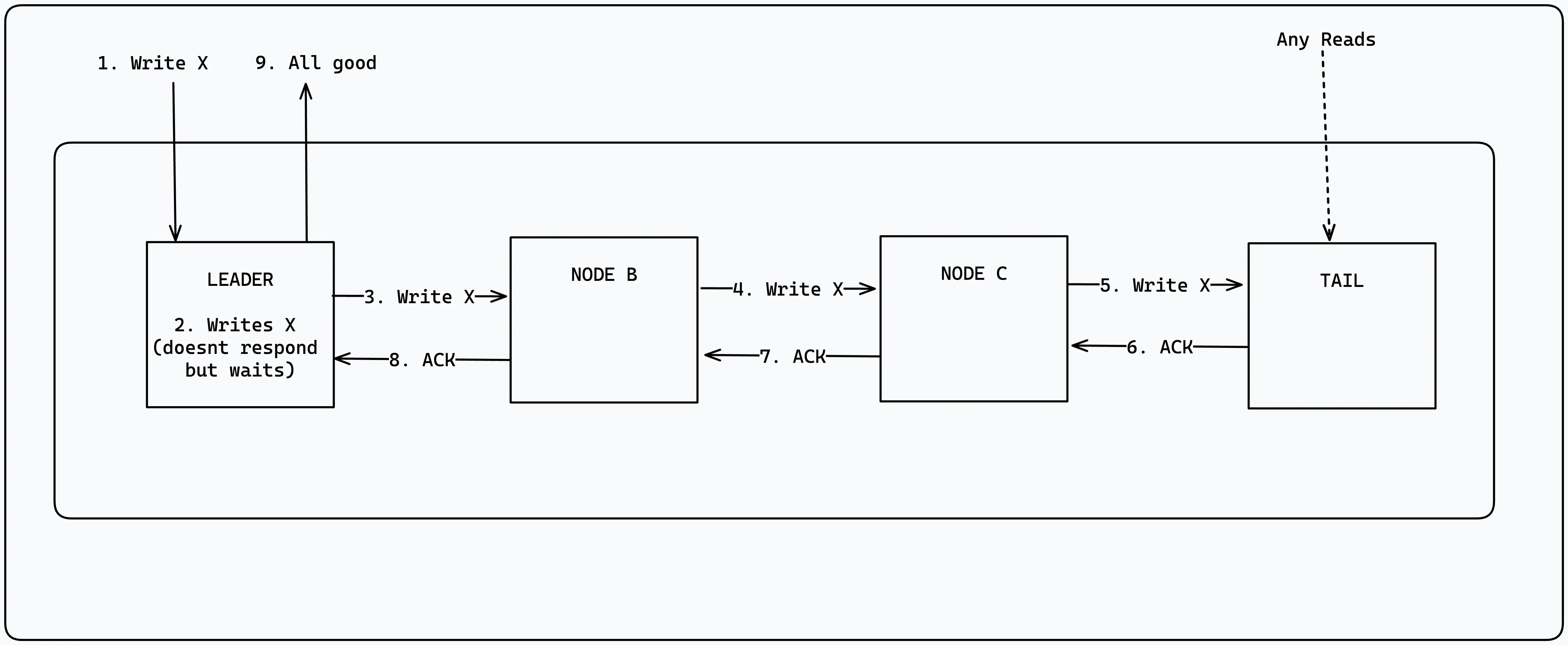
Fault tolerance is controlled by a separate component known as the control plane. The control pane monitors the chains health and when it detects a faulty process, it will remove it from the chain and connect the nodes on either side of the faulty node. A downside to Chain Replication is the potential for a large write latency. Since any updates need to propagate down the chain before it can be acknowledged, the write latency is the sum of the latency of each node in the chain.
You can read more about Chain Replication here: Chain Replication - how to build an effective KV storage by Anton Zagorskii or Chain Replication for Supporting High Throughput and Availability
Leader Election
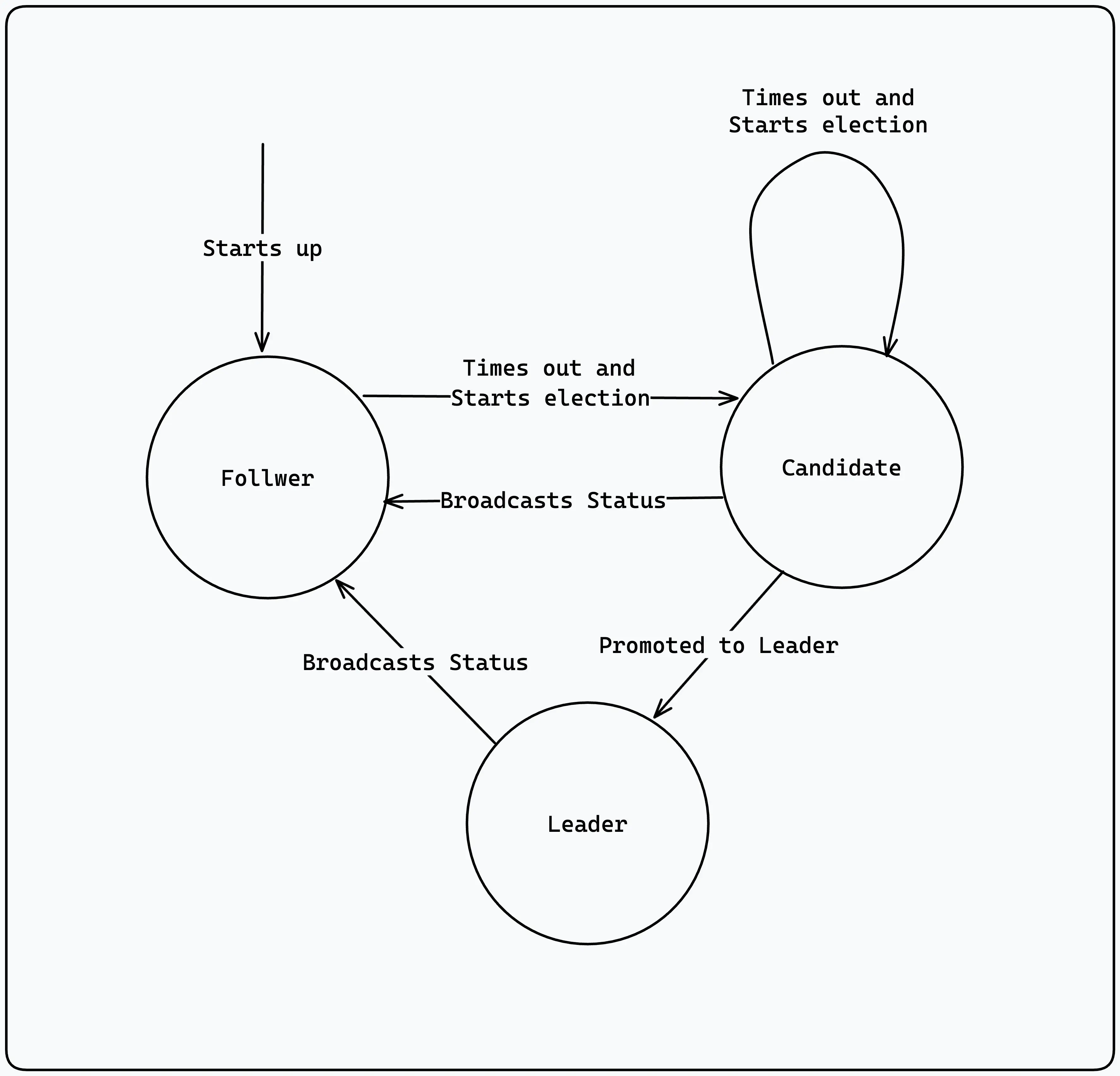
One thing I've glossed over in the post is the concept of Leader Election. Which node is the leader? how is that decided? What happens if the leader fails? How do we elect a new leader? These are all questions that need to be answered in a distributed system. Leader election is a complex topic and I will not go into it in this post. I will however link to some resources that explain it in more detail. But let's look at an algorithm called the Rafts Leader election algorithm which is implemented as a state machine, where any node is in one of three possible states.
- Follower
- Candidate
- Leader
With the Raft Leader Election algorithm, time is divided into 'election terms' which are numbered with consecutive integers. A term will begin with a new election, where a candidate node will attempt to become the leader. An election is triggered when a follower node does not receive a message from the leader node. The leader is then presumed dead and the follower will transition to a Candidate.
The candidate will broadcast itself to Followers who will vote for it on a first come first serve basis. If the candidate receives a majority of votes, it will become the leader. If the candidate does not receive a majority of votes, it will transition back to a follower and wait for the next election term. In the unlikely event that a period goes by with no winner then the election will time out and a new election will begin. The election timeout value is randomly picked on each candidate to prevent the likelihood of multiple candidates causing a split vote for a second time.
Benefits of Distributed Systems
Despite the challenges they present, distributed systems offer a range of compelling advantages.
Performance and Scalability: Distributed systems can be designed to handle large volumes of data and process it in parallel, resulting in faster performance and reduced latency. This is especially important for applications that require real-time data processing, such as online gaming and financial trading. Distributed systems can also be designed to scale horizontally, allowing for the addition of more nodes to increase processing power and performance. This is in contrast to traditional single-node systems, which are limited by the processing power of a single machine.
Resilience and redundancy: Distributed systems are designed to be fault-tolerant, meaning they can continue to operate in the event of a node failure. This is achieved through the use of replication, which allows for the storage of multiple copies of data across a network of nodes. In the event of a node failure, the data can be retrieved from another node, ensuring the system remains operational. This is in contrast to traditional single-node systems, which are vulnerable to data loss in the event of a node failure.
Cost efficiency: Distributed systems can be designed to run on commodity hardware, which is significantly cheaper than specialized hardware. This allows for the creation of cost-effective solutions that can be scaled up or down as needed. This is in contrast to traditional single-node systems, which require expensive hardware to achieve the same level of performance.
Efficiency and speed: Distributed systems can be designed to process data in parallel, resulting in faster performance and reduced latency. This is especially important for applications that require real-time data processing.
Conclusion
In conclusion, this high-level overview has provided a glimpse into the world of distributed systems. From their foundational concepts to the challenges they address and the benefits they offer, distributed systems are at the heart of modern computing. As technology continues to advance, the role of distributed systems will only become more integral, influencing the way we build and interact with applications in an increasingly interconnected world.
As I get my feet more dirty in the world of distributed systems and data, I'll share my learnings and findings here.

Found my content useful and want to help support me? Consider buying me a coffee.